Nvidia在Hugging:如何使用Nvidia的Hugging Face Transformer提高自然语言处理能力
Nvidia近期发布了其最新的自动语音识别(ASR)模型Parakeet-TDT-0.6B-v2,具备6亿个参数,能够在一秒内转录60分钟音频。该模型使用FastConformer编码器和TDT解码器架构,性能优异,已在多个ASR基准上经过严格评估。它支持多种应用,包括转录服务和语音助手,并提供标点符号和详细时间戳的转录解决方案。开发者可以通过Nvidia的NeMo工具包轻松部署该模型,兼容Python和PyTorch。Parakeet-TDT-0.6B-v2在不同噪声条件下表现良好,并可在低配置系统上运行,增强了其可用性。Nvidia承诺在开发过程中遵循负责任的AI框架,未使用个人数据,并提供了全面的文档以确保隐私合规性。该模型的开源特性吸引了广泛关注,尤其在机器学习和开源社区。
 AI的最新动态与独家内容
AI的最新动态与独家内容加入我们的每日和每周通讯,获取关于领先AI发展的最新更新和独家见解。这些通讯为行业专业人士和爱好者提供了宝贵的信息,确保您能够及时了解快速发展的人工智能领域。
 Nvidia对AI技术的影响
Nvidia对AI技术的影响近年来,Nvidia已成为全球最有价值的公司之一,这主要得益于对图形处理单元(GPU)日益增长的需求。这些强大的芯片由Nvidia制造,对于视频游戏中的图形渲染以及日益增多的用于训练大型语言和扩散模型的人工智能来说至关重要。然而,Nvidia的贡献不仅限于硬件;该公司还开发软件以优化其使用。
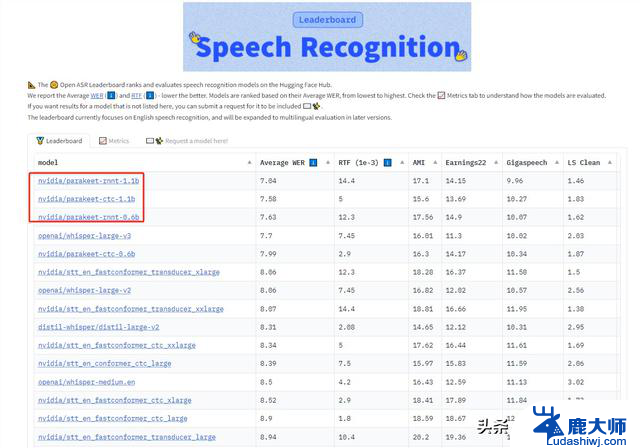
随着生成式AI时代的持续发展,总部位于美国加利福尼亚州圣克拉拉的Nvidia不断推出多种自有的AI模型。这些模型大多为开源,供研究人员和开发者下载、修改并用于商业目的。最新发布的模型是Parakeet-TDT-0.6B-v2,这是一种自动语音识别(ASR)模型。可以在仅一秒钟内转录60分钟的音频,正如Hugging Face的Vaibhav “VB” Srivastav所强调的那样。
 Parakeet-TDT-0.6B-v2的性能与特性
Parakeet-TDT-0.6B-v2的性能与特性Parakeet-TDT-0.6B-v2模型拥有令人印象深刻的6亿个参数,采用了FastConformer编码器和TDT解码器架构的组合。在Nvidia的GPU加速硬件上,它能够在短短一秒内转录一小时的音频。其性能基准记录为RTFx(实时因子)3386.02,批量大小为128,位于Hugging Face维护的当前ASR基准的前沿。
该模型于2025年5月1日在全球发布,目标用户为开发者、研究人员和行业团队,致力于转录服务、语音助手、字幕生成器和对话AI平台等应用。该模型支持标点符号、大小写和详细的逐字时间戳,为多样化的语音转文本需求提供了全面的转录解决方案。
模型的可获取性与开发开发者可以使用Nvidia的NeMo工具包部署Parakeet-TDT-0.6B-v2。该设置与Python和PyTorch兼容,允许直接使用或针对特定任务进行微调。开源许可证(CC-BY-4.0)允许商业使用,使其成为初创公司和大型企业的一个有吸引力的选择。
该模型是在一个多样化且广泛的数据集上训练的,称为Granary数据集,包含约120,000小时的英语音频。该数据集包括10,000小时的高质量人工转录数据和110,000小时的伪标注语音,来源于知名数据集如LibriSpeech和Mozilla Common Voice,以及YouTube-Commons和Librilight。Nvidia计划在2025年Interspeech大会后公开发布Granary数据集。
评估与兼容性Parakeet-TDT-0.6B-v2在多个英语ASR基准上经过严格评估,包括AMI、Earnings22、GigaSpeech和SPGISpeech,展现出强大的泛化性能。它在不同噪声条件下依然有效,且在电话音频格式下表现优异,在较低信噪比时仅有轻微的性能下降。
该模型针对Nvidia GPU环境进行了优化,支持A100、H100、T4和V100等硬件。尽管高端GPU提供最佳性能,但该模型也可以在仅有2GB RAM的系统上部署,扩大了其在不同应用场景中的可用性。
AI开发中的伦理考量Nvidia强调,Parakeet-TDT-0.6B-v2的开发未使用个人数据,并遵循其负责任的AI框架。虽然没有采取具体措施来应对人口统计偏见,但该模型满足内部质量标准,并提供了关于其训练过程、数据集来源和隐私合规性的全面文档。
该模型的发布引起了机器学习和开源社区的关注,尤其是在社交媒体平台上被广泛讨论。观察者指出,该模型不仅在性能上超越了商业ASR替代品,同时仍然保持完全开源并可用于商业用途。对此模型感兴趣的开发者可以通过Hugging Face或Nvidia的NeMo工具包获取,并提供现成的安装说明、演示脚本和集成指南。以支持实验和部署。
Nvidia在Hugging:如何使用Nvidia的Hugging Face Transformer提高自然语言处理能力相关教程
- ServiceNow、Hugging Face和NVIDIA联合开放LLM,助力生成式AI在企业应用领域的应用
- 微软Xbox AI聊天机器人测试:用自然语言获取Xbox支持
- 微软GitHub Spark革新开发体验:自然语言构建应用成为现实
- 三星Exynos 2400芯片发布:CPU性能提升70%,AI处理能力提升1470%
- NVIDIA 人工智能开讲 | AI For Science:研究领域新突破的AI助力
- NVIDIA终于修复了Linux上显卡游戏性能损失问题,性能提升高达20%
- 骁龙8 Gen3处理器性能曝光:CPU提升30%,NPU翻倍,A17 Pro压力巨大
- NVIDIA 的历程:从游戏显卡到 AI 先驱!- 探索NVIDIA如何由游戏显卡制造商发展为人工智能领域的先驱
- 6款大学生爱用的windows软件,个个功能强大,助力学习提高效率
- Win7如何优化系统性能提升使用体验,教你快速提升电脑速度
- 为什么网友觉得Windows XP和Windows 7是最经典的版本?这两个操作系统的特点让人无法忘怀
- NVIDIA亮相SIGGRAPH 2025:推出全新Cosmos世界模型,颠覆视觉体验!
- Windows系统最新实用工具软件推荐:建议收藏 - 2021年最受欢迎的Windows工具推荐
- 微软云电脑:Windows 365主设备坏了也不用愁,微软会借给你一台云电脑
- 万丽推出静谧黑版RTX 50系星际显卡,RTX 5070等GPU全新上市
- **网购显卡防骗指南**
微软资讯推荐
- 1 为什么网友觉得Windows XP和Windows 7是最经典的版本?这两个操作系统的特点让人无法忘怀
- 2 **网购显卡防骗指南**
- 3 美国用户指控微软终止支持Win10逼迫用户升级设备
- 4 2025年8月最新CPU天梯图出炉!英特尔、AMD谁主沉浮?最新比较分析
- 5 微软Win11 Canary预览版27919发布:系统搜索设置整合优化
- 6 NVIDIA终于修复了Linux上显卡游戏性能损失问题,性能提升高达20%
- 7 微软发布 Windows 2030 战略:AI 与语音交互重塑 PC 未来,智能化助力未来PC发展
- 8 显卡性能全开指南,3A游戏卡顿终结者!- 让你的游戏体验更加流畅
- 9 “欧盟版”Windows 11竟这么清爽?你也能轻松优化的秘诀揭晓
- 10 你真懂吗?显卡的生产力性能究竟是什么?解析
win10系统推荐
系统教程推荐
- 1 windows10flash插件 如何在Win10自带浏览器中开启Adobe Flash Player插件
- 2 台式机win10怎么调节屏幕亮度 Win10台式电脑如何调整屏幕亮度
- 3 笔记本电脑怎样设置密码开机密码 如何在电脑上设置开机密码
- 4 笔记本键盘不能输入任何东西 笔记本键盘无法输入字
- 5 苹果手机如何共享网络给电脑 苹果手机网络分享到台式机的教程
- 6 钉钉截图快捷键设置 电脑钉钉截图快捷键设置方法
- 7 激活windows7家庭普通版密钥 win7家庭版激活码序列号查询
- 8 wifi有网但是电脑连不上网 电脑连接WIFI无法浏览网页怎么解决
- 9 适配器电脑怎么连 蓝牙适配器连接电脑步骤
- 10 快捷删除是哪个键 删除快捷键ctrl加alt