重大进展!国产CPU DCU完美“接盘”Nvidia环境,加速中国自主芯片发展!
近日,有工程师给出一组测试数据。详细展示了客流统计算法从Nvidia环境往国产海光CPU+DCU进行迁移的训练过程,最终结果让人振奋——
基于海光CPU+DCU,在完全采用历史训练代码,不做任何修改的前提下,就能完成整个训练!
该测试以公共场所中的客流信息统计为场景,验证了pytorch和paddlepaddle两种主流的深度学习框架。以及目标检测、行人重识别和多标签分类三种类型的深度学习任务,详细对比了Nvidia GPU和Hygon DCU两种硬件环境下的训练结果。
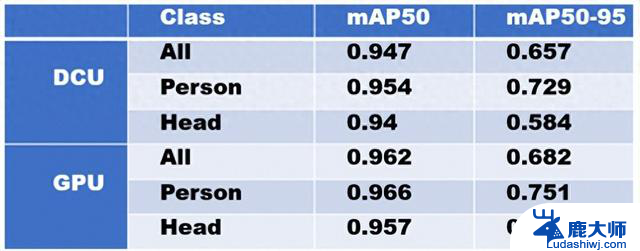
目标检测模型训练数据显示,在训练速度上,海光DCU与Nvidia GPU基本一致,都在平均每秒4次迭代左右(4 it/s);在精度上,根据测试集上的表现,两者相差仅2个百分点;从部分推理结果图来看,DCU和GPU训练出来的模型在推理时表现几乎一样,连预测的置信度都没有差异。
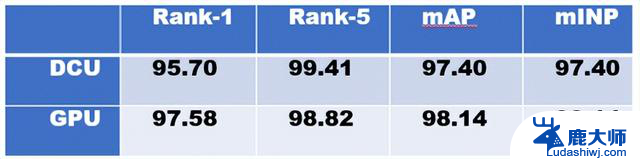
行人重识别模型训练结果显示,在训练速度上,GPU机器平均每次迭代0.65s(0.65s/it),DCU机器平均每次迭代1.34s(1.34s/it),因为采用的是完全相同的训练设置,这里的速度差异应该是由于训练数据加载导致;在精度上,两者在测试集上的数据相差不到2个百分点;识别结果图也基本符合预期。
多标签图像分类模型训练中,海光DCU表现明显更加优异,训练结束后的精度对比中,两者的差异在1个百分点之内;训练速度上,DCU机器和GPU机器差异巨大。其中DCU训练的吞吐量约1410images/sec,GPU训练的吞吐量约194images/sec,在保持精度稳定的基础上,DCU的训练吞吐量堪称惊艳;另外最后的识别结果样例图效果也同样不错。
从总体的使用体验上来看,海光DCU在相同配置环境中,与Nvidia CPU的PK结果远远超出了预期。更难得的是在性能表现达标的基础上,省略了大量修改代码的流程,解决了国内AI厂商最为头疼的适配难题,实现了真正的低成本无痛迁移。
重大进展!国产CPU DCU完美“接盘”Nvidia环境,加速中国自主芯片发展!相关教程
- 英伟达7月向中国提供新芯片,加速中国人工智能发展
- 阿里巴巴自主研发AI芯片,应对NVIDIA在华市场限制,开启中国AI芯片竞争新篇章
- 英伟达获批对华出口“阉割版”芯片,凸显美国尴尬窘境
- Nvidia因美国新的芯片限制政策,或将损失50亿美元中国订单
- 近2000万美金月费!TikTok成微软AI大户,加速AI技术发展
- 国产操作系统崛起,微软面临挑战,后续发展如何?
- 英伟达(NVIDIA)发展史:从图形芯片巨头到人工智能领军者
- 强强联合 国产系统深度适配龙芯CPU!助力中国科技自主创新
- 6大国产CPU中,有2大已经胜出了?如何选择最佳的国产CPU
- 英伟达市值超过苹果,“中国英伟达”价值几何?-探讨中国GPU巨头的发展潜力
- 2K游戏战场再添利器!蓝宝石黑钻RX 9060 XT 16G D6 OC显卡助力游戏性能提升
- AI算力需求带动英伟达业绩增长,英伟达在AI算力市场表现强劲
- Windows系统入侵痕迹自查指南:如何检查Windows系统是否遭到入侵
- NVIDIA旧显卡安全凭证即将到期,如何保障您的设备安全?
- AMD的GPU,野心暴露:全新显卡即将发布,性能再创新高
- AMD锐龙9000F/PRO 9045处理器接近发售,已上线海外电商,性能强劲,抢购热潮即将来袭
微软资讯推荐
- 1 2K游戏战场再添利器!蓝宝石黑钻RX 9060 XT 16G D6 OC显卡助力游戏性能提升
- 2 Windows系统入侵痕迹自查指南:如何检查Windows系统是否遭到入侵
- 3 NVIDIA旧显卡安全凭证即将到期,如何保障您的设备安全?
- 4 AMD的GPU,野心暴露:全新显卡即将发布,性能再创新高
- 5 阿里巴巴自主研发AI芯片,应对NVIDIA在华市场限制,开启中国AI芯片竞争新篇章
- 6 砺算首款显卡对标英伟达4060,实控人台湾籍,2年融资数亿!
- 7 显卡交火为什么不流行了?现在的显卡技术已经足够强大吗?
- 8 Windows的“掉盘”BUG,为何会演变成了“霸凌”现象?
- 9 微软Win11 23H2八月可选更新:修复简中输入和设备管理BUG
- 10 AMD台式机独显首次引入LPDDR6/5X,将取代GDDR成为显存标准
win10系统推荐
系统教程推荐
- 1 windows10flash插件 如何在Win10自带浏览器中开启Adobe Flash Player插件
- 2 台式机win10怎么调节屏幕亮度 Win10台式电脑如何调整屏幕亮度
- 3 笔记本电脑怎样设置密码开机密码 如何在电脑上设置开机密码
- 4 笔记本键盘不能输入任何东西 笔记本键盘无法输入字
- 5 苹果手机如何共享网络给电脑 苹果手机网络分享到台式机的教程
- 6 钉钉截图快捷键设置 电脑钉钉截图快捷键设置方法
- 7 激活windows7家庭普通版密钥 win7家庭版激活码序列号查询
- 8 wifi有网但是电脑连不上网 电脑连接WIFI无法浏览网页怎么解决
- 9 适配器电脑怎么连 蓝牙适配器连接电脑步骤
- 10 快捷删除是哪个键 删除快捷键ctrl加alt